

不止是反推:为什么说OllamaVisionKit是LoRA训练的“降维打击”?
如果你是一名严肃的AI创作者,尤其是在LoRA训练领域,你一定明白“Garbage in, garbage out”的道理。数据集的质量,直接决定了你“炼丹”的成败。传统的反推工具(如DeepDanbooru、WD1.4 Tagger)在特定领域表现出色,但它们有两大“天花板”:固化的认知和有限的控制力。
而我开发的这款 OllamaVisionKit 插件,正是为了突破这两个天花板。它并非简单地调用一个API,而是将强大的、通用的本地视觉大模型(VLM)与精密的指令工程相结合,为你提供前所未有的数据集控制力。
质的区别一:从“关键词匹配”到“视觉理解”
传统反推工具的本质,是一个巨大的“标签-图像特征”分类器。它看到一张图,输出的是它“字典里”最匹配的关键词。这在动漫领域很有效,但面对现实世界、复杂的艺术风格或非主流概念时,就显得力不心从心。
OllamaVisionKit利用的是真正的视觉语言模型(如LLaVA, Qwen-VL)。这意味着:
- 超越标签库的认知: VLM不依赖固定的标签库。它能像人一样**“理解”并“描述”画面内容。一张包含“蒸汽朋克风格的机械猫头鹰在维多利亚时代的图书馆里”的图片,传统工具可能会识别出“bird, clock, library”,而VLM则能生成一段准确描述其关系、氛围和风格**的文本。
- 上下文推理能力: VLM能够理解复杂的场景和交互。它不仅能看到“一个女孩”和“一把剑”,还能推断出“一个女孩正准备拔出插在石头里的剑”,这种对动作、意图和关系的描述能力,是传统工具无法比拟的。
质的区别二:从“被动接受”到“主动控制”
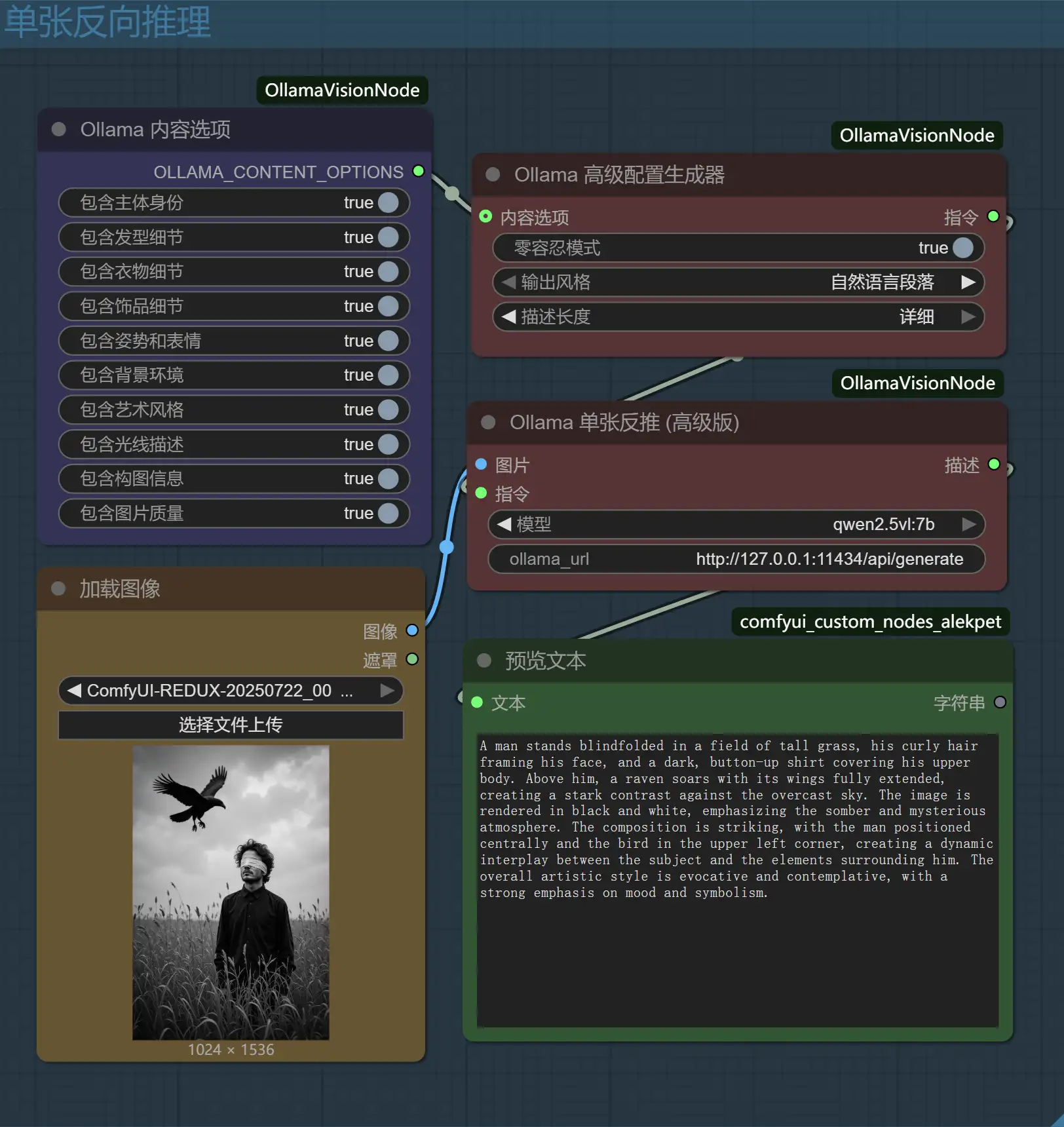
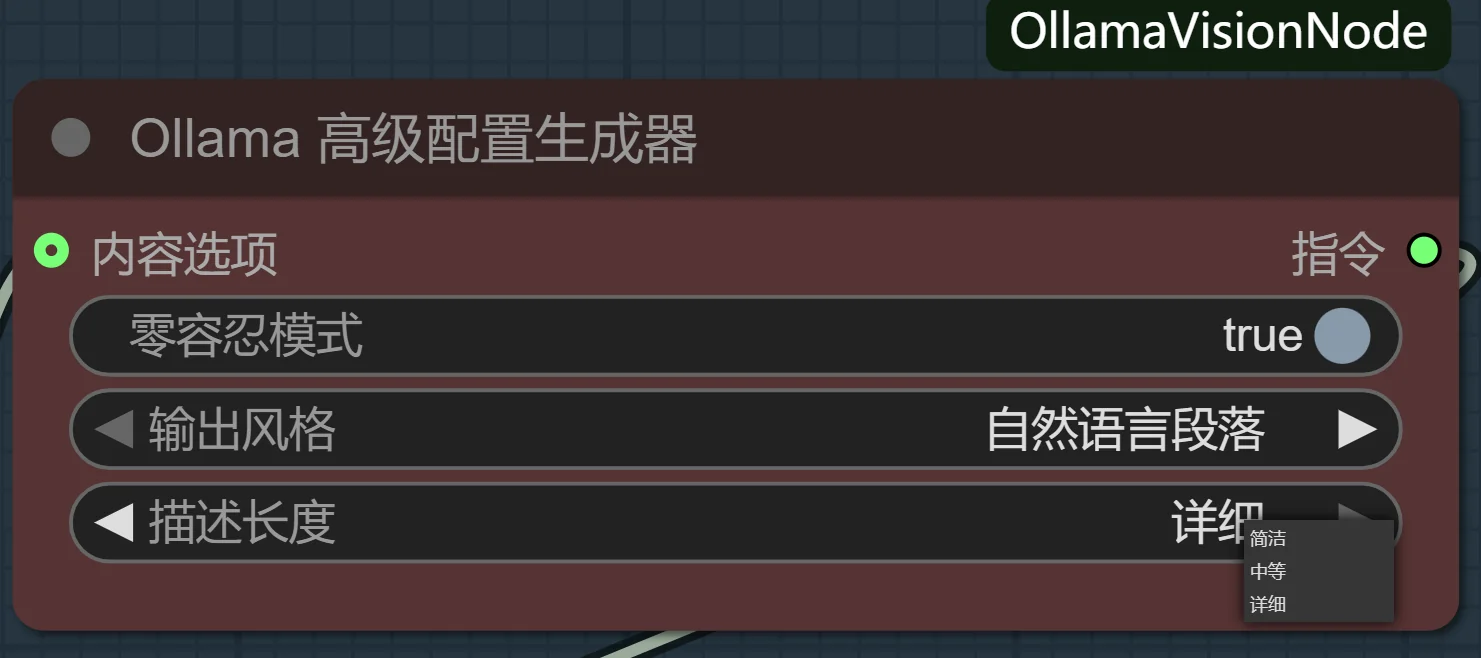
传统工具的输出是固定的,你几乎无法干预它的分析过程。而OllamaVisionKit的核心,就是那个强大的高级配置生成器,它让你从一个被动的标签接受者,变成一个主动的指令下达者。
这套丰富的设定,就是你区别于普通玩家的“开发者模式”:
-
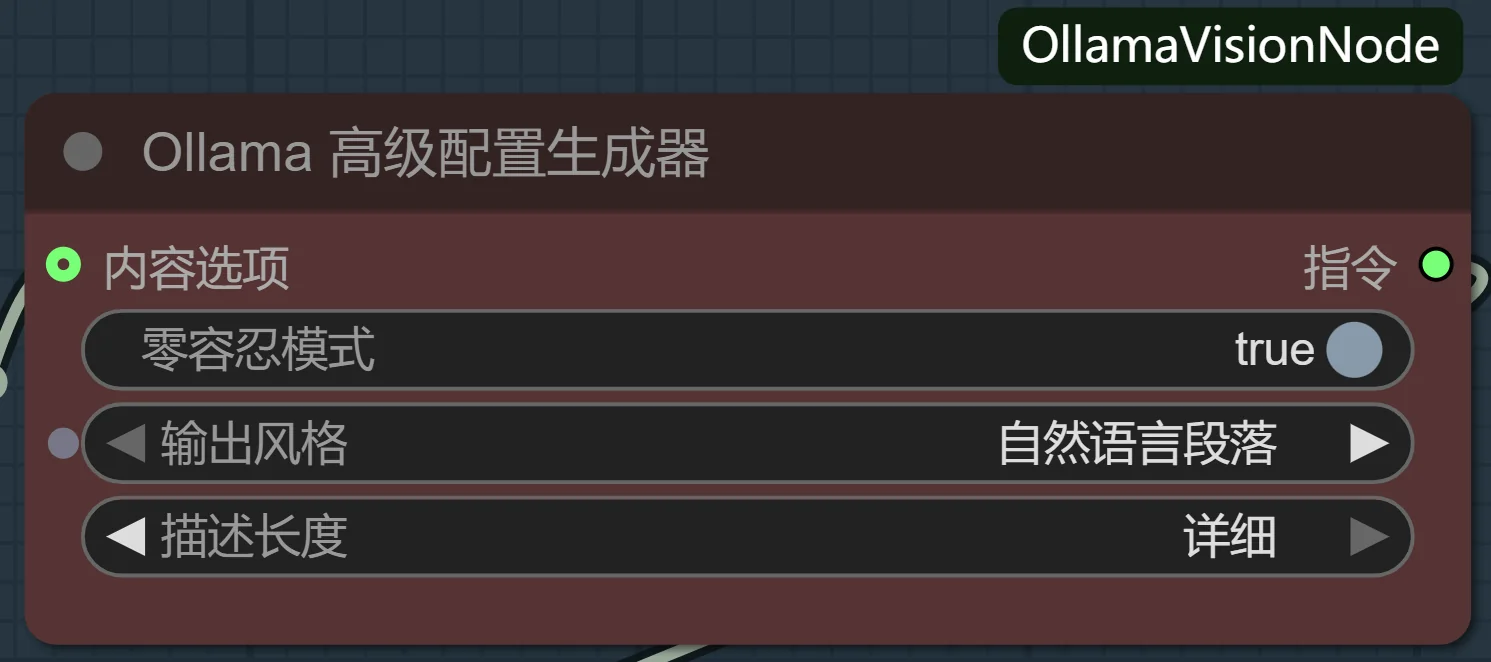
“零容忍”模式——对抗模型幻觉的利器: 这是我最引以为傲的功能。开启它,插件会生成一段包含强否定约束的指令,强制VLM进入一种“事实核查”模式。它会抑制VLM为了语言流畅性而“脑补”细节的倾向。对于LoRA训练,这意味着你的数据集中不会出现“图片里明明是短裙,标签却写了连衣裙”这种致命错误,极大提升了数据集的保真度。
-
-
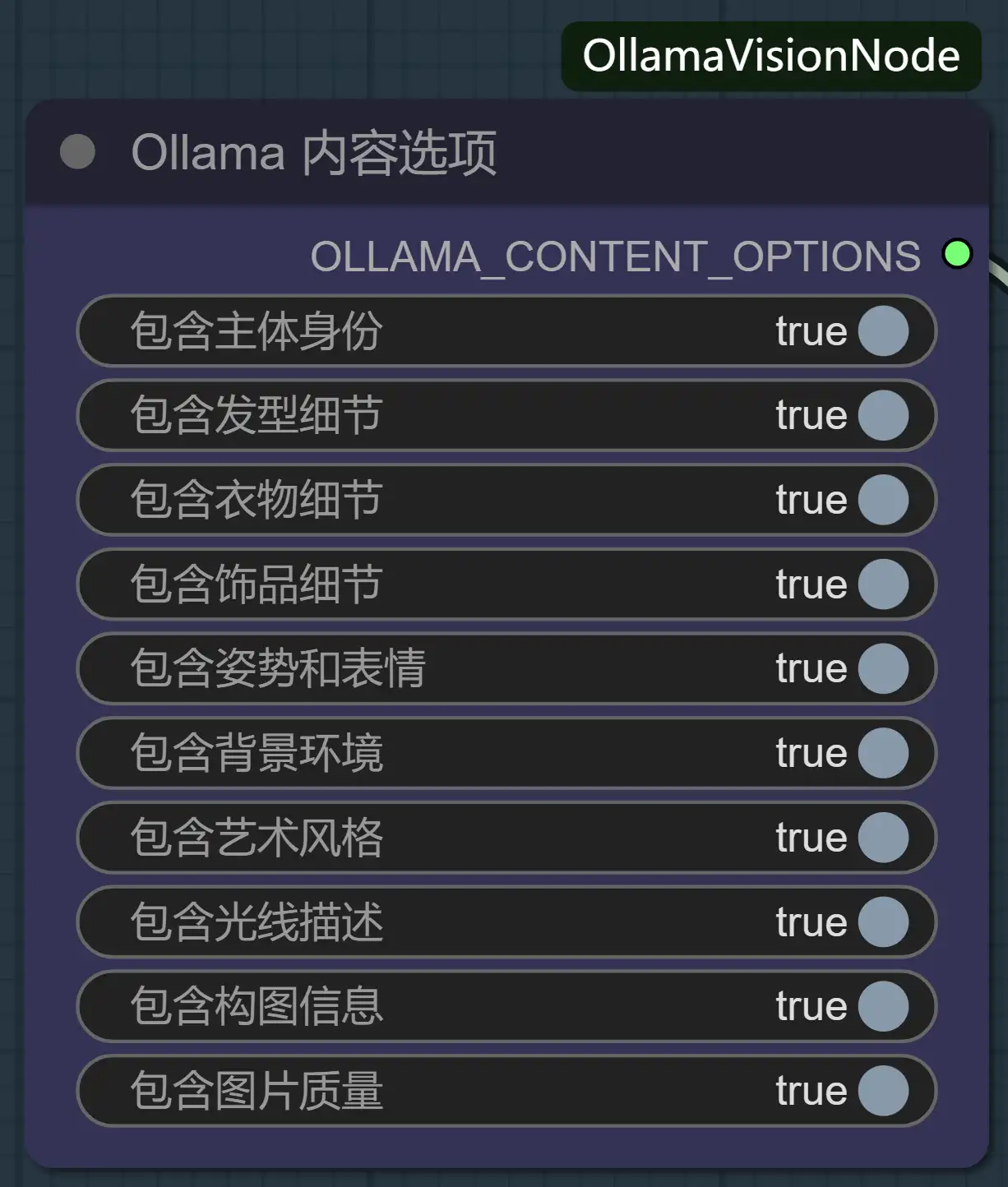
内容开关矩阵——手术刀般的精准分析: 你想训练一个“角色LoRA”,但又不希望模型被背景和服装干扰?在传统工作流中,你需要在反推后手动删除大量无关标签。现在,你只需在
内容选项节点里,关闭“背景环境”和“衣物细节”的开关。插件会自动生成指令,引导VLM在分析时“无视”这些元素。反之,训练“风格LoRA”时,你可以关闭所有主体描述,只保留构图、光线等抽象元素。这种在分析源头就进行过滤的能力,是颠覆性的。 -
-
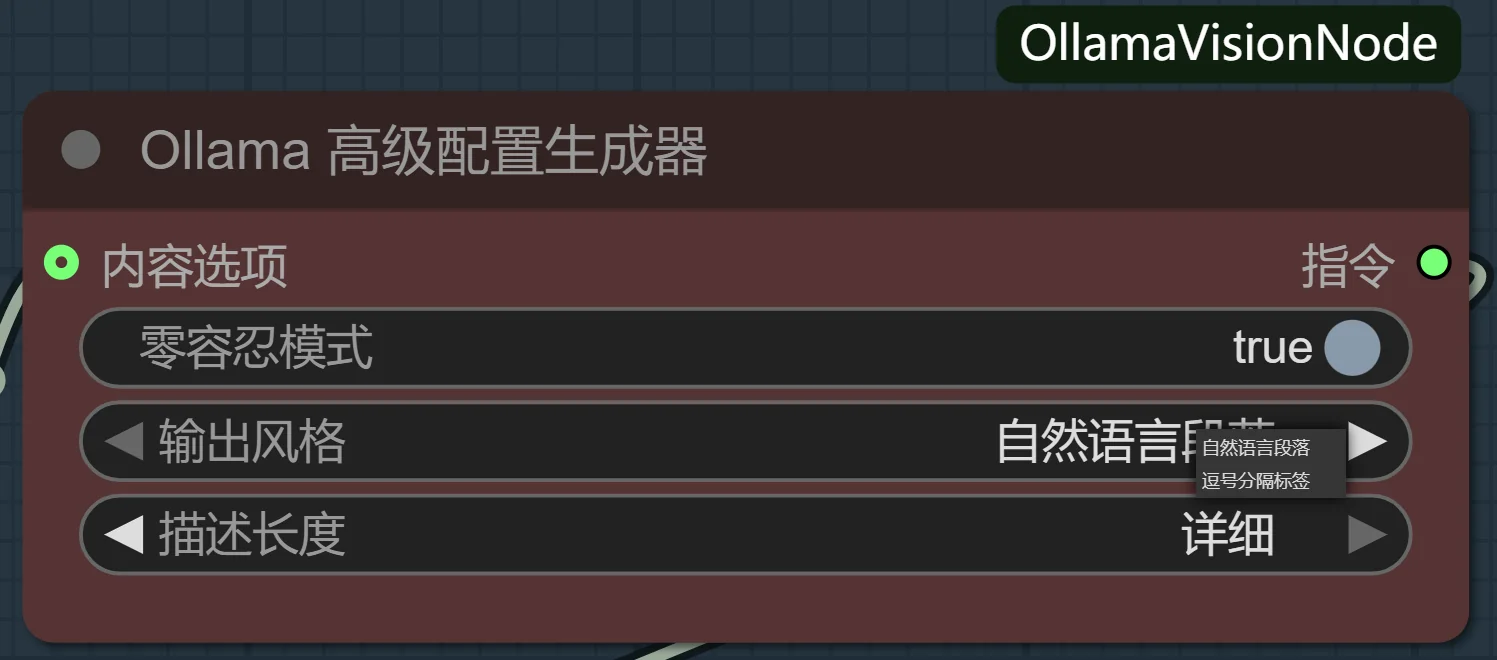
长度与风格控制——为不同应用场景定制输出: 你需要的是用于训练的、简洁的逗号分隔标签,还是用于发布作品时详细、富有文采的自然语言描述?这个设定让你可以在“数据工程师”和“艺术评论家”两种角色间无缝切换,一份图源,两种用途。
-
-
为什么我需要这个插件?
简单来说,OllamaVisionKit解决了传统反推工具的两个核心痛点:
- 它用更强大的“大脑”(VLM)取代了固化的“字典”,让分析的深度和广度有了质的飞跃。
- 它用一套完整的“控制系统”(高级配置生成器)取代了“黑箱操作”,让你能前所未有地精确主导AI的分析过程。
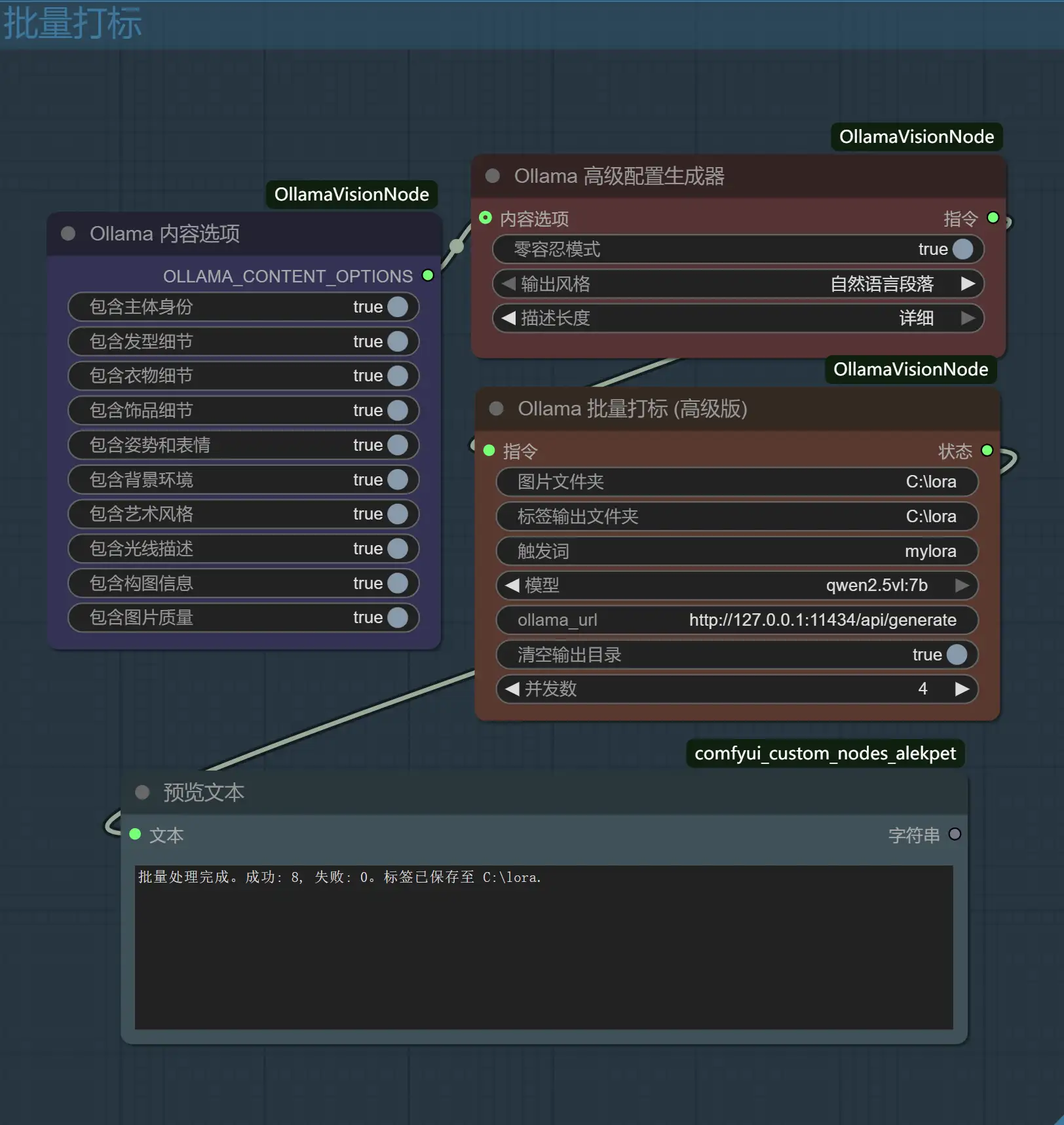
再加上高性能的并发批量处理和无缝的UI体验,它构成了一个完整、高效且专业的视觉数据处理方案。
- 全自动批量打标:支持指定输入/输出文件夹,自动处理图片并生成同名.txt标签文件。
- 高性能并发处理:可自定义并发线程数,充分利用多核CPU,大幅缩短处理时间。内置实时UI进度条和详细的控制台日志。
- 精准的Prompt工程:内置一个“高级配置生成器”,可以通过UI选项(如零容忍模式、输出风格、描述长度、内容开关)来动态生成高质量的分析指令,有效避免模型幻觉,控制标签粒度。
- 双模式执行:提供“单张反推”用于快速分析和测试,“批量打标”用于生产环境。
- 体验优化:自动扫描并加载本地Ollama模型,无需手动输入。
对于追求极致效果的LoRA炼丹师和希望深度理解AI视觉能力的探索者来说,OllamaVisionKit不是一个“可选项”,而是一个能帮你构建起代差优势的“必需品”。
安装插件前提条件
在开始之前,请确保您已完成以下设置:
-
Ollama 已安装并正在运行: 本插件需要您在本地安装并运行 Ollama。在启动ComfyUI之前,请确保Ollama应用程序正在后台运行。
-
已下载视觉模型
您至少需要安装一个视觉语言模型(VLM)。我们强烈推荐您从
qwen2.5vl:7b开始,因为它在性能和资源占用之间取得了出色的平衡。您可以在终端(命令行)中运行以下命令来下载它:
ollama pull qwen2.5vl:7b
安装
在满足前提条件后:
- 将本仓库克隆到您的
ComfyUI/custom_nodes/目录下:
git clone https://github.com/chinggirltube/OllamaVisionKit.git- 或者,您也可以下载
__init__.py文件,并将其放入ComfyUI/custom_nodes/目录下一个名为OllamaVisionKit的新文件夹中。 - 重启ComfyUI。您现在应该可以在
Ollama分类下找到新的节点。