

CodeZen:我为自己打造了一个“中文 GitHub 雷达”,告别信息过载
从“信息消费者”到“工具创造者”
你是否和我一样,每天都在 X(前 Twitter)或技术社区里被动地接收着各种“今日热门 GitHub 项目”的推送?
起初,我觉得这很棒。总有一些博主或账号孜孜不倦地为我们筛选出那些新奇、有趣、值得关注的开源项目。但时间一长,我发现自己陷入了一种新的困境:
- 信息茧房:我看到的一切,都是经过别人筛选和定义的“好东西”。他们的标准就是我的天花板。
- 信息延迟:当一个项目被广泛推送时,它往往已经错过了最初的“引爆点”。
- 信息过载:推送的内容良莠不齐,很多项目虽然热门,却与我的技术栈或兴趣点毫不相干。
- 信息遗忘:那些曾经让我眼前一亮的项目,很快就被新的信息流淹没,当我真正想找回它时,却如同大海捞针。
我意识到,我不能只当一个“信息消费者”。我需要一个属于自己的雷达,一个能根据我的规则,为我扫描、过滤并沉淀信息的工具。
于是,一个想法诞生了:我为什么不自己动手,打造一个全自动的、专注中文区的 GitHub 项目发现平台呢?
这个想法最终的结晶,就是我引以为豪的个人项目——CodeZen。
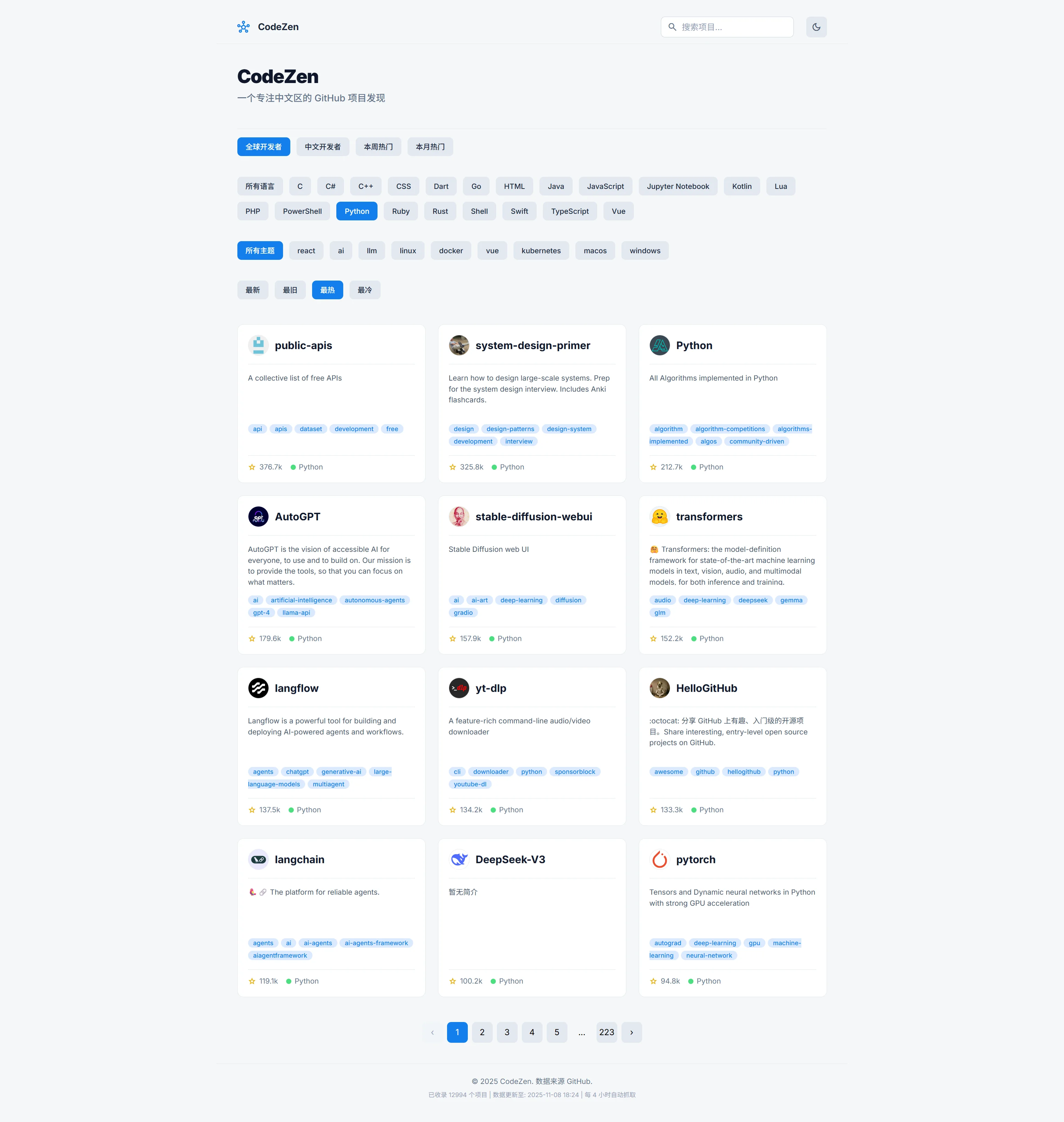
CodeZen 的核心哲学:你的规则,你的世界
CodeZen 的设计初衷,就是要解决上面提到的所有痛点。它不仅仅是一个简单的信息聚合器,更是一个遵循我个人哲学的智能系统:
-
主动探索,而非被动接收:CodeZen 的后台机器人不知疲倦,它按照我设定的精确规则(例如:“7天内创建”、“Star数超过50”),主动向 GitHub 的浩瀚星海发起探索。
-
中文优先,但不排斥世界:我是一名中文开发者,能快速理解的中文文档对我至关重要。CodeZen 的核心算法之一就是“智能中文内容识别”。它能穿透项目的
description,深度扫描README.md甚至README_CN.md,精准地判断一个项目是否对中文友好。同时,它也提供了一键切换“全球开发者”/“中文开发者”的视野,让我既能聚焦本土,也能放眼世界。 -
沉淀价值,而非阅后即焚:所有被 CodeZen 雷达捕获的项目,都会被永久地存入我的个人数据库。这构成了一个可搜索、可过滤的“灵感宝库”。我可以随时回来,根据语言、主题甚至热度,找到一年前发现的那个项目。
技术之旅:从一个 Python 脚本到一个全功能 Web 应用
CodeZen 的进化之路,是一次浓缩版的软件开发之旅。它经历了从一个简单的后端脚本,到最终成为一个功能完备的全栈应用的蜕变。
V1.0:Telegram Bot 推送时代
最初,它只是一个运行在我 VPS 上的 Python 脚本,通过 cron 定时执行,将新发现的项目推送到我的 Telegram。这解决了主动探索的问题,但“信息遗忘”的问题依然存在。
V2.0:Web 界面的诞生 我很快意识到,线性的消息流无法承载一个知识库的使命。于是,我用 Flask 搭建了第一个 Web 界面。数据不再是“推送后消失”,而是被优雅地展示在一个个卡片上。这是从“信息流”到“数据库”的关键转变。
V3.0:智能与自动化 随着项目的演进,简单的分离部署变得繁琐。我将数据抓取和 Web 服务整合进一个应用,并引入了 APScheduler 来实现内置的自动化调度。现在,只需要运行一个进程,CodeZen 就能实现 7x24 小时的自我更新。
V4.0:“终极形态”—— CodeZen 的诞生 这是最大的一次进化,我几乎重构了所有核心功能:
- 历史数据回填器:为了让平台上线伊始就拥有丰富的历史数据,我专门编写了一个
backfiller.py脚本。它像一台“时光机”,从 2015 年开始,逐月扫描 GitHub 历史,将那些曾经闪耀过的、符合高标准(例如 >800 Star)的项目全部“追溯”回收,为 CodeZen 奠定了坚实的数据基础。 - HTMX 赋能的现代化前端:为了追求极致的用户体验,我选择了轻量而强大的 HTMX。现在,所有的筛选、排序和翻页操作都实现了无刷新局部加载,带来了如丝般顺滑的交互体验。
- “初衷”排序算法:我设计了一套“二级排序”算法,解决了“最新”和“最热”的排序矛盾,让你总能看到最想看的内容。
- 丰富的数据维度:抓取并展示了作者头像、项目主题(Topics),并实现了按语言、主题的动态过滤。
最终,这个曾经不起眼的小工具,成长为了我每天必看的个人信息中心——CodeZen。
CodeZen 的核心功能一览
- 全自动数据抓取:内置调度器,每 4 小时自动从 GitHub 抓取增量数据。
- 历史数据回填:一次性工具,可抓取自 2015 年以来的所有高价值历史项目。
- 智能中文识别:深度扫描
README,优先采用纯中文文档内容。 - 多维度筛选:支持按关键词、编程语言、热门主题进行组合筛选。
- “初衷”排序:提供“最新/最旧/最热/最冷”四种智能排序模式。
- 无刷新体验:基于 HTMX 的现代化前端,所有操作即时响应,无需等待页面重新加载。
- 深色/浅色模式:适应不同环境下的阅读需求。
创造自己的工具,是开发者的终极浪漫
从一个解决个人痛点的简单想法,到一个功能完备、体验流畅的 Web 应用,CodeZen 的开发过程让我收获巨大。它不仅是一个实用的工具,更是我技术热情和创造力的证明。
如果你也曾被信息的洪流所困扰,如果你也渴望打造一个属于自己的、能沉淀价值的工具,我希望 CodeZen 的故事能给你带来一些启发。
欢迎访问我的仓库,查看 CodeZen 的全部源码。
仓库地址:https://git.wlens.top/laowang/CodeZen